
Source:
greatsynthesizers.com



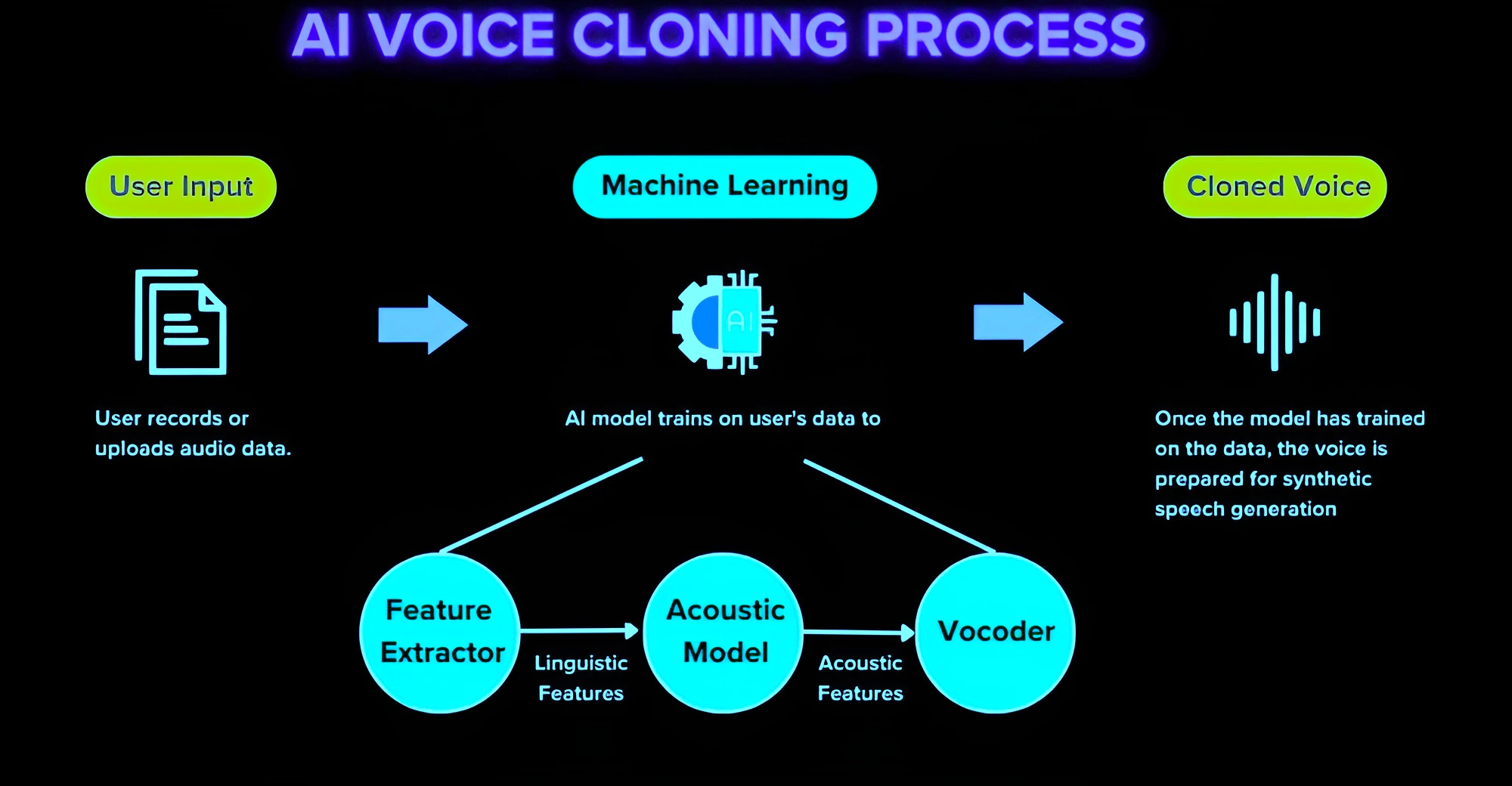
Artificial Intelligence is no longer limited to generating text or images—it is now transforming the very fabric of sound. From composing original music to cloning human voices with astonishing precision, neural audio synthesis is redefining how we create and experience audio. But with great innovation comes equally significant ethical and legal challenges.
Neural audio synthesis refers to the use of deep learning models to generate sound directly as raw audio waveforms. Unlike traditional music production tools that rely on pre-recorded samples or MIDI inputs, these AI systems create entirely new audio from scratch.
A groundbreaking example is OpenAI Jukebox, a neural network capable of producing full songs—including vocals—in specific genres and even mimicking artist styles. It works by compressing audio into a simplified representation and then reconstructing it using advanced neural architectures.
What makes this revolutionary is its ability to capture subtle musical elements like:
This marks a shift from “AI-assisted music” to AI-created music.
Voice cloning takes neural audio synthesis a step further. Instead of generating generic voices, AI can now replicate a specific person’s voice using minimal data.
Modern systems can:
Research shows that neural models can successfully clone voices using only a handful of samples, making the technology highly accessible.
In fact, some experimental tools can recreate a voice with as little as 15 seconds of audio, raising both excitement and alarm.
Tools like OpenAI Jukebox can:
Despite its promise, this technology comes with serious challenges.
AI can generate songs or speeches that sound like real artists or public figures—without their consent. This creates:
Who owns a voice?
As AI-generated voices become indistinguishable from real ones, legal systems are struggling to define:
Artists and celebrities are increasingly raising concerns about unauthorized use of their vocal likeness.
Voice cloning can be exploited for:
Experts warn that audio deepfakes may be harder to detect than visual ones, increasing their potential for harm.
Neural audio synthesis is still evolving, but its trajectory is clear:
The key challenge will be balancing innovation with responsibility—ensuring that creators are protected while still enabling technological progress.
Neural audio synthesis and voice cloning represent one of the most fascinating frontiers of AI. From generating songs in the style of legends to recreating human voices with uncanny accuracy, the technology is both creative and disruptive.
However, as AI begins to blur the line between real and synthetic sound, society must confront critical questions about authenticity, ownership, and trust.
In the end, the voice of the future may not always belong to a human—but how we choose to use it will define the sound of tomorrow.





 Select Option
Select Option
